
A Ray of light in scaled Generative AI
Building, customizing, and deploying Large Language Models using Ray.io framework


This week I would like to make a step forward in presenting the opportunity of running advanced local AI capabilities (like models fine-tuning, retrieval augmented generation, langchain-based applications, etc…) based on open source frameworks specifically designed for CPU.
After Neural-Speed, NeuralChat, auto-round, and Intel Extension for Transformers, it’s time to play with llm-on-ray,
Before embarking in the exploration of Intel/llm-on-ray, we need to take some time to discover the framework on which it is based: Ray.io by Anyscale.
Ray.io
Ray.io is a powerful framework developed by Anyscale to scale the coding and the deployment of Python applications from our consumer-grade hardware to a more capable data center or cloud infrastructure: easily parallelize and distribute ML workloads across multiple nodes and CPUs/GPUs
So, it’s easy to understand why it’s so interesting for the rows of this blog: ray.io allows to create something big directly on your machine.
Ray.io consists in two main components: the first one is the Ray.io Core, a distributed runtime that enables applications to be built directly in pure Python and that can be deployed in three different ways:
Running Ray.io as a task: lets you run stateless functions as remote tasks in the cluster, so you can fetch them later as object reference with a
ray.get;Calling Ray.io actors: stateful worker processes created in the cluster to allow parallelization of computation across multiple instances (a.k.a. actors). In this way, when a class is instantiated as Ray.io actor, a remote instance of that class starts in the cluster and the actor can then execute remote method calls maintaining its own internal state;
Passing an object: immutable values accessible across the cluster created explicitly as object references via ray.put and then passed to tasks as substitutes for argument values.
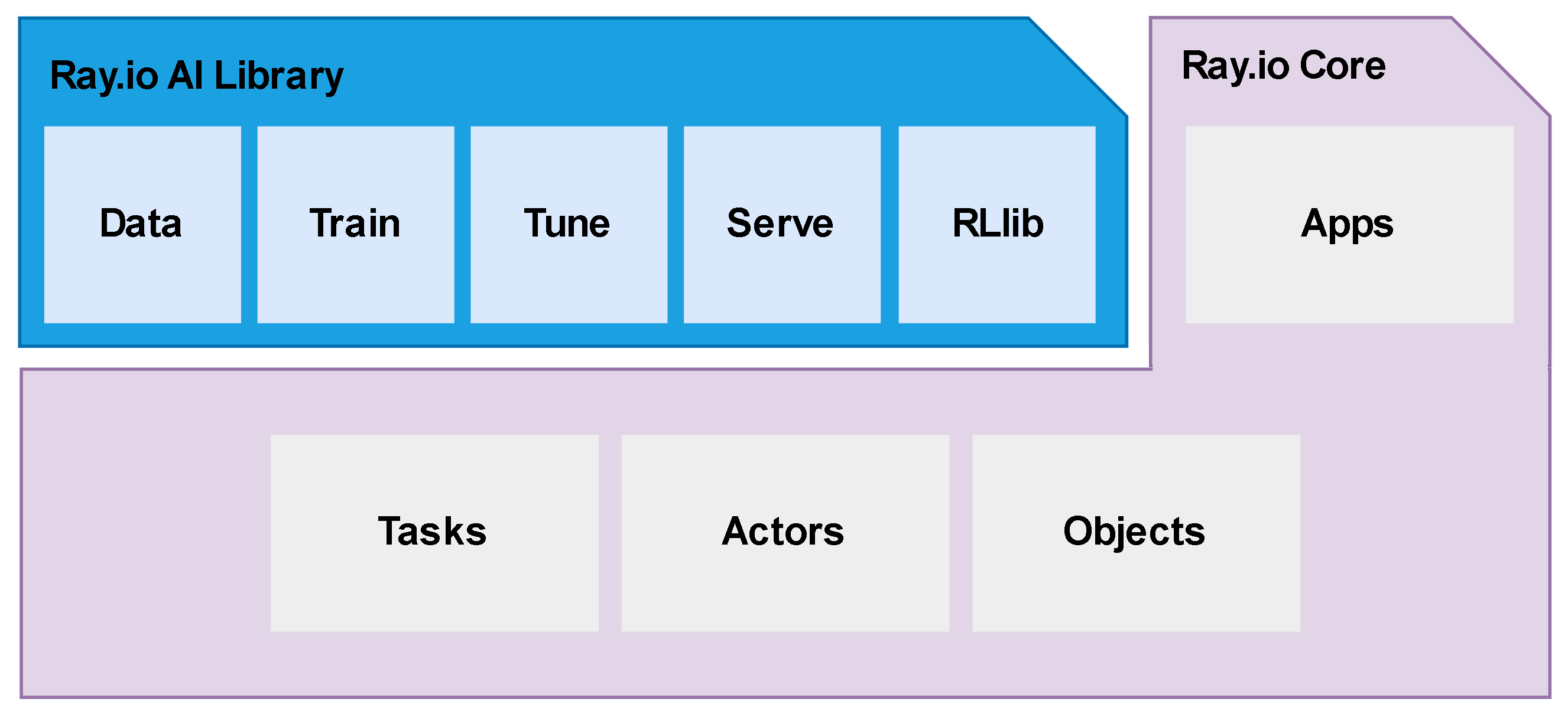
The second component of the architecture, as complement, is composed by a set of libraries:
Data: scalable data processing library for AI workloads; it provides flexible and performant APIs for scaling Offline batch inference and Data preprocessing and ingest for ML training. Ray Data uses streaming execution to efficiently process large datasets.
Train: scalable machine learning library for distributed training and fine-tuning; it allows to scale model training code abstracting the complexities of distributed computing.
Tune: python library for experiment execution and scalable hyperparameter; it’s compatible with a variety of machine learning frameworks (PyTorch, XGBoost, TensorFlow and Keras, etc…) by running modern algorithms such as Population Based Training (PBT) and HyperBand/ASHA. It also further integrates with a wide range of additional hyperparameter optimization tools, including Ax, BayesOpt, BOHB, Nevergrad, and Optuna.
Serve: scalable model serving library for building online inference APIs; it’s framework-agnostic, so you can use a single toolkit to serve everything from deep learning models built with frameworks like PyTorch, TensorFlow, and Keras, to Scikit-Learn models. It offers several features and performance optimizations for serving Large Language Models such as response streaming, dynamic request batching, multi-node/multi-GPU serving, etc.
RLlib: reinforcement learning (RL) library; it’s ready for production-level environment, plus as highly distributed RL workloads.
Overview of llm-on-ray
Mixing notable Intel’s frameworks for AI and the distributable capabilities of Ray.io, Intel developed LLM-on-Ray: a comprehensive solution designed to deploy a production-ready LLM endpoint service scaling it as needed efficiently.
The modular workflow allows to take every step of LLM deployment, from local pc pre-training and fine-tuning, to final inference serving: LLM-on-ray includes a set of tools for preprocessing training data (data preparation) such as removal of Personally Identifiable Information (PII) and data deduplication (Dedup).
LLM-on-Ray has been developed with compatibility in mind: it is cross-available to be deployed on various hardware setups, including Intel CPU, Intel GPU and Intel HPU (es Gaudi2), this architecture allows us to pretrain and finetune the model directly on our pc, then scale bigger.
Finally, LLM-on-Ray incorporates several industry frameworks optimizations to maximize performance, including vLLM, llama.cpp, Intel Extension for PyTorch/DeepSpeed, IPEX-LLM, RecDP-LLM, NeuralChat and more.
Preparing the Environment
As previously, we need to setup a protected virtual environment where we can experiment:
~$ git clone https://github.com/intel/llm-on-ray.git
~$ cd llm-on-ray
~/llm-on-ray$ conda create -n llm-on-ray -c intel python=3.9
~/llm-on-ray$ conda activate llm-on-raySetup and Ignite
Install LLM-on-ray is quite straight forward, as we require just to build a python wheel binary package to install with pip directly from the sources:
(llm-on-ray) ~/llm-on-ray$ pip install .[cpu] --extra-index-url https://download.pytorch.org/whl/cpu --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/cpu/us/Now, you can start Ray.io.
As we presented in the introduction, Ray.io supports a distributed deployment solution, so you can start it as only-node or multi-node.
On the primary node (—head) run Ray.io with just the command:
(llm-on-ray) ~/llm-on-ray$ ray start --head --node-ip-address 127.0.0.1 --dashboard-host='0.0.0.0' --dashboard-port=8265If you want to deploy a multi-node cluster, on the additional node(s) you’ll need to prepare the environment and the workspace folder as you did for the main node, then attach the additional worker(s) to the cluster with:
(llm-on-ray) ~/llm-on-ray$ ray start --node-ip-address 127.0.0.1 --address='<MAIN_NODE_IP>:6379'Then, let’s check if the dashboard is accessible through the URL http://<MAIN_NODE_IP>:8265

Configure Serving Parameters
Let’s create a new configuration file to deploy an inference server.
I decided to go forward with openlm-research/open_llama_7b_v2 because I strongly believe in open source development for AI frameworks (Datasets, models, architectures, and training methods/processes), especially in Natural Language Generation field. So I want support OpenLM Research Lab.
We are going to create a new file with the command:
(llm-on-ray) ~/llm-on-ray$ nano llm_on_ray/inference/models/openlm-research_open_llama_7b_v2.yamlThen, compile the file with the following info:

Where:
—port is the interfacing port for API calls
—name is the internal name to identify different instance unique configurations
—route_prefix is path to append to URL for https requests
—num_replicas is the number of replicas you request to ray.io cluster
—dynamic_max_batch_size is the maximum number of allowed request per single batch
—cpus_per_worker is the number of available cpu threads available on ray.io cluster
—gpus_per_worker is the number of available gpu devices available on ray.io cluster
—workers_per_group is the number of workers per group
—device is the primary device to use: gpu, hpu or cpu
—model_id_or_path Language model ID on HuggingFace.co or local pathdir where the model has been downloaded
—tokenizer_name_or_path Model tokenizer ID on HuggingFace.co or local pathdir where the model has been downloaded
And boom!

Serve Inference
Now, let’s tray to serve our model. And here comes the magic of Ray.io: you can serve different models, on multiple replicas, through several endpoints, on the same machine; adding nodes to the cluster scaling automatically (or manually) as needed.
With the following command, we are creating a new endpoint to serve inference of openlm-research/open_llama_7b_v2
(llm-on-ray) ~/llm-on-ray$ llm_on_ray-serve --config_file llm_on_ray/inference/models/openlm-research_open_llama_7b_v2.yaml --simpleMust return:
[INFO 2024-06-09 19:06:15,088] client.py: 496 Deployment 'PredictorDeployment:ke2259rb' is ready at `http://0.0.0.0:8000/open_llama_7b_v2`. component=serve deployment=PredictorDeployment
2024-06-09 19:06:15,094 INFO handle.py:126 -- Created DeploymentHandle 'ot2uam99' for Deployment(name='PredictorDeployment', app='openlm-research_open_llama_7b_v2').
2024-06-09 19:06:15,094 INFO api.py:584 -- Deployed app 'openlm-research_open_llama_7b_v2' successfully.
Deployment 'openlm-research_open_llama_7b_v2' is ready at `http://127.0.0.1:8000/open_llama_7b_v2`.
Service is deployed successfully.
It will be served at the http://<MAIN_NODE_IP>:8000/open_llama_7b_v2.
Again, I want to stress the point: you can run several different inference servers; check the llm_on_ray/inference/models folder to check other yaml files as example.
You can check which endpoints are available in the Serve section of Ray.io’s Dashboard.

Testing Endpoint
Let us test the endpoint using the test scripts available in the examples/inference/api_server_simple folder of the repository: 1) query_single.py is useful to test a single text completion, 2) query_dynamic_batch.py allows to check the completion of a batch of prompts.
Obviously, you can run the serve endpoint using a different machine.
(llm-on-ray) ~/llm-on-ray$ python examples/inference/api_server_simple/query_single.py --model_endpoint http://<MAIN_NODE_IP>:8000/open_llama_7b_v2{"text":"Once upon a time, there was a little girl who loved to play with her dolls. She had a collection of dolls that she loved to play with. She had a collection of dolls that she loved to dress up. She had a collection of dolls that she loved to take care of. She had a collection of dolls that she loved to play with.","input_length":6,"generate_length":128}
(llm-on-ray) ~/llm-on-ray$ python examples/inference/api_server_simple/query_dynamic_batch.py --model_endpoint http://<MAIN_NODE_IP>:8000/open_llama_7b_v2{"text":"Once upon a time, there was a little girl who lived in a small town. She was a very happy girl, and","input_length":10,"generate_length":20}
--------------
{"text":"Hi my name is Lewis and I like to make things.\nI am a freelance web developer and designer based in the UK. I have been","input_length":10,"generate_length":20}
--------------
{"text":"My name is Mary, and my favorite color is purple. I am a 20-something year old college student who loves to read","input_length":10,"generate_length":20}
--------------
{"text":"My name is Clara and I am a 20 year old student from the Netherlands. I am currently studying International Business and Management at","input_length":10,"generate_length":20}
--------------
{"text":"My name is Julien and I like to make things.\nI'm a software engineer and I'm currently working at the University of","input_length":10,"generate_length":20}
--------------
{"text":"Today I accidentally deleted a file from my desktop. I was trying","input_length":7,"generate_length":10}
--------------
{"text":"My greatest wish is to be able to help people. I have been a","input_length":7,"generate_length":10}
--------------
{"text":"In a galaxy far far away, there is a planet called Earth. On this","input_length":7,"generate_length":10}
--------------
{"text":"My best talent is my ability to listen. I am a good listener","input_length":7,"generate_length":10}
Total responses: 9
References
Advanced Ray Serve Autoscaling on Ray.io Documentation
LLM-on-Ray on Github
License
This work is licensed under Creative Commons Attribution 4.0 International