
Advanced Weight-only Quantization Technique on CPU
SignRound by Intel, lightweight block-wise tuning using signed gradient descent


When LLMs started spreading at the end of 2022, it sounded something really impossible: training or even just fine-tune a model on your modest customer-grade hardware was fantasy.
Now, in the middle of 2024, thanks to an intensive work of scientific research, considerable investment, open governance, open collaboration, and a good dose of human ingenuity, we are now able to fine-tune models directly on our devices. Incredibile!
In this article I am going to showcase a process that will take advantage of a methodology that it is strictly connected to elements I already presented in my first post (Efficient LLM Inference on CPUs) and it has been developed by Intel Researchers (Wenhua Cheng et al.). That technique, named SignRound, was published for the first time in the scientific paper titled Optimize Weight Rounding via Signed Gradient Descent for the Quantization of LLMs arXiv:2309.05516v2 in date 2023, September 28th.
The Method
The standard flow involves the tensor quantization of both weights and activations, but, as probably you already know, it increases the training complexity, requires a longer training times and requires hyperparameters to be carefully tuned which is particularly costly in terms of computational costs (and consequentially power angry and expensive hardware).
So, weight-only quantization gained favourable trade off for LLMs tuning as it’s a more practical choice for most case scenarios.
In order to quantize the weights we need to perform a rounding operation, through RTN (rounding-to-nearest) method: each element will independently quantized by simply rounding it to the nearest integer.
The problem is that RTN fails to consider the relationships weights-weights (as for weights-activations), and it introduces substantial weights modifications that may make other terms significant and non-negligible.
SignRound uses signed gradient descent method to address the issue of sub-optimal rounding solutions: it is used to fine-tune the rounding up and the rounding down through a block-wise output reconstruction to fasten the convergence.
Mathematical magic? This method does not introduce any additional overhead during the inference.
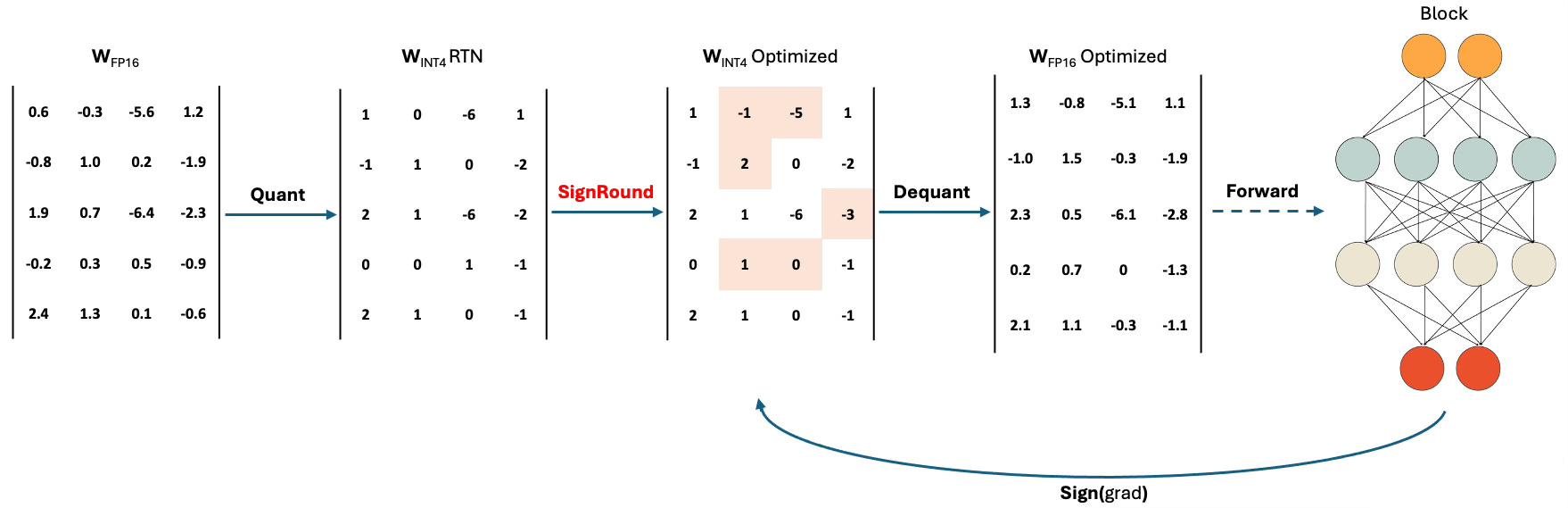
After lightweight forward and backward steps, INT4 space has been well optimized towards the minimal loss, therefore ready for the final inference deployment. In figure, Quant and Dequant are two standard operations for quantization and dequantization respectively.
From Math to Code
SignRound methodology has been implemented in Intel auto-round, an open source algorithm library for low-bits LLM inference written in python (version ≥3.9, version=3.11 suggested) that anyone can access freely on github.com/intel/auto-round.
Intel auto-round performs well in HuggingFace.co’s low_bit_open_llm_leaderboard.
The core of auto-round algorithm lies in intel/auto-round/tree/main/auto_round and it can easily be installed directly through pip, but I suggest to build it from sources, as it follows.

Preparing our Environment
Ok, as always, I want to line things up properly. Let us create a virtual-environment thought Conda, that we can use as a sandbox to tinker with auto-round python package and its dependences.
So,
Create a new virtual-env;
Activate it;
Clone auto-round repository;
enter the folder;
install preliminary requirements;
build auto-round from its sources and install it in the virtual environment as python wheel.
~$ conda create -c intel -n auto-round python=3.11
~$ conda activate auto-round
(auto-round) ~$ git clone https://github.com/intel/auto-round
(auto-round) ~$ cd auto-round
(auto-round) ~/auto-round$ pip install -r requirements.txt
(auto-round) ~/auto-round$ pip install .Ok, now we should have all the trumps to start experimenting with Auto-Round.
Language Modeling
Now, let’s just to a specific folder, where you will find a script called language-modeling:
(auto-round) ~/auto-round$ cd examples/language-modelingInside that folder there is all you need to apply SOTA Weight-only Quantization Algorithm to our LLM in just one move.
For example, do you want to quantize mistralai/Mistral-7B-Instruct-v0.2 to enlighten it in INT4/group_size 128 and to run inference using just your CPU?
Just type
(auto-round) ~/auto-round/examples/language-modeling$ mkdir models
(auto-round) ~/auto-round/examples/language-modeling$ cd models
(auto-round) ~/auto-round/examples/language-modeling$ huggingface-cli download --resume-download --local-dir mistralai_Mistral-7B-Instruct-v0.2 --local-dir-use-symlinks False mistralai/Mistral-7B-Instruct-v0.2 --token <YOUR_HUGGINGFACE_TOKEN>
(auto-round) ~/auto-round/examples/language-modeling$ cd ..
(auto-round) ~/auto-round/examples/language-modeling$ python3 main.py \
--model_name ./models/mistralai_Mistral-7B-Instruct-v0.2 \
--device auto \
--group_size 128 \
--bits 4 \
--iters 1000 \
--deployment_device 'cpu' \
--scale_dtype 'fp32' \
--eval_bs 32 \
--output_dir "./tmp_autoround"Note: guide to generate your HuggingFace personal security token <YOUR_HUGGINGFACE_TOKEN> here.
You eventually avoid the step to download the model using huggingface-cli, just passing as argument the HuggingFace ID, but I find it a good practise to trace everything on my storage, and reuse it if/when needed.

Be Patient!
As we are talking about to use our dated hardware to achieve this task, you know you’ll need to be patient, we don’t need to rush.
To quantize my version of model, I used a consumer-grade GPU based on NVIDIA RTX 3060 and a 4060 with the final goal of running inference on devices using only CPU and RAM.
To quantize Mistral-7B-Instruct-v0.2 the process took:
NVIDIA GeForce RTX 4060 Ti 8.37 hours
NVIDIA GeForce RTX 3060 10.51 hours
By comparison, quantization process of Phi-2 on a NVIDIA GeForce RTX 2060 took 4.85 hours.
During the wait, you can check the additional arguments you can input for language-modeling/main.py:
--train_bs TRAIN_BS Train batch size.
--eval_bs EVAL_BS Eval batch size.
--device DEVICE The device to be used for tuning. The default is set to auto, allowing for automatic detection. Currently, device settings support CPU, GPU, and HPU.
--sym sym (symmetric) quantization. Default is off, for asym (asymmetric).
--iters ITERS iters
--dataset DATASET The dataset for quantization training. It can be a custom one.
--lr LR learning rate, if None, it will be set to 1.0/iters automatically.
--minmax_lr MINMAX_LR minmax learning rate, if None,it will beset to be the same with lr.
--seed SEED Seed to be used, integer.
--eval_fp16_baseline Whether to eval FP16 baseline.
--adam Automatic rounding-based quantization with optimizers like adamw of a PyTorch model.
--seqlen SEQLEN Sequence length.
--gradient_accumulate_steps GRADIENT_ACCUMULATE_STEPS Gradient accumulate steps.
--n_blocks N_BLOCKS num of blocks to tune together.
--n_samples N_SAMPLES number of samples.
--deployment_device DEPLOYMENT_DEVICE Targeted inference acceleration platform. The options are 'fake', 'cpu' and 'gpu'.default to 'fake', indicating that it only performs fake quantization and won't be exported to any device.
--scale_dtype SCALE_DTYPE Which scale data type to use for quantization, 'fp16', 'fp32' or 'bf16'.
--tasks TASKS lm-eval tasks for lm_eval version 0.4.
--output_dir OUTPUT_DIR Where to store the final model.
--disable_eval Whether to do lmeval evaluation.
--disable_amp Disable amp.
--disable_low_gpu_mem_usage Disable the mechanism that allows to save gpu memory usage.
--disable_minmax_tuning Whether disable enable weight minmax tuning.
--disable_trust_remote_code Whether to disable trust_remote_code.
--disable_quanted_input whether to disuse the output of quantized block to tune the next block.
--quant_lm_head quant_lm_head.
Conclusion
On the online repository you can find a set of pre-coded scripts with all recipes to quantize in INT4, group_size 128 the following models with suggested arguments for an optimal conversion: Intel/neural-chat-7b-v3-3, Intel/neural-chat-7b-v3-1, mistralai/Mistral-7B-v0.1, microsoft/phi-2, microsoft/phi-3-mini, tiiuae/falcon-7b, google/gemma-2b, mistralai/Mistral-7B-Instruct-v0.2, google/gemma-7b, google/gemma-7b-it, mistralai/Mixtral-8x7B-Instruct-v0.1, mistralai/Mixtral-8x7B-v0.1, meta-llama/Meta-Llama-3-8B-Instruct, meta-llama/Llama-2-7b-chat-hf, Qwen/Qwen1.5-7B-Chat, baichuan-inc/Baichuan2-7B-Chat, 01-ai/Yi-6B-Chat, facebook/opt-2.7b, bigscience/bloom-3b, upstage/SOLAR-10.7B-Instruct-v1.0, meta-llama/Meta-Llama-3-8B-Instruct, and EleutherAI/gpt-j-6b.
Intel also provides us a series of pre-quantized (INT4, group_size 128) models using auto-round: these models are available con HuggingFace.co/Intel.
Intel/neural-chat-7b-v3-3 HF-int4-model
Intel/neural-chat-7b-v3-1 HF-int4-model
mistralai/Mistral-7B-v0.1 HF-int4-model
microsoft/phi-2 HF-int4-model
tiiuae/falcon-7b HF-int4-model
google/gemma-2b HF-int4-model
mistralai/Mistral-7B-Instruct-v0.2 HF-int4-model
google/gemma-7b HF-int4-model
google/gemma-7b-it HF-int4-model
mistralai/Mixtral-8x7B-Instruct-v0.1 HF-int4-model
mistralai/Mixtral-8x7B-v0.1 HF-int4-model
upstage/SOLAR-10.7B-Instruct-v1.0 HF-int4-model
microsoft/phi-3-mini HF-int4-model
meta-llama/Meta-Llama-3-8B-Instruct HF-int4-model
From the inference side, with INT4/group_size 128 quantization of Mistral-7B-Instruct-v0.2, I reached 44.69 tokens/s loading the model using ExLlamav2_HF on a RTX 4060 Ti GPU.
References
Cheng et al., Optimize Weight Rounding via Signed Gradient Descent for the Quantization of LLMs arXiv:2309.05516v2 [cs.CL] 28 Sep 2023
Official Intel auto-round repository on Github
License
This work is licensed under Creative Commons Attribution 4.0 International