
Neural Speed, Advanced Usage
Dig into the many many options of Intel Neural Speed.


After an initial presentation and a second follow up, here the third episode of my excursus about weight-only quantization, SignRound technique and their code implementation: the tensor parallelism library and inference engine, Neural Speed.
It is an amazing tool, and makes sense to explore a little more all the opportunities it offers through its multiple options.
I would like to start from the series of one-click scripts that Developers behind Neural Speed have implemented to make easier to interact with the library.
Before starting, remember you need to re-activate the conda environment we previously created, then enter the root of directory where you previously downloaded the sources.
$ conda activate neural-speed
(neural-speed) $ cd neural-speed Which models are supported?
Neural Speed supports almost all the LLMs in PyTorch format (.safetensors) from HuggingFace such as Llama/Llama2, ChatGLM2, Baichuan2, Qwen, Mistral/Mixtral, Whisper, etc…; typical LLMs in .gguf format such as Llama2, Falcon, MPT, Bloom are also supported.
Neural Speed assumes the compatible model format as llama.cpp and ggml.
A comprehensive scheme of supported models with quantization methods and additional details about max context tokens length, transformer version, and per purpose is available at docs/supported_models.md.
Step 1: conversion with scripts/convert.py
Let us to decompose every single step in order to take full advantage of Neural Speed starting with the very first one: the conversion of the model using the script convert.py.
This script is really useful because already include the call for huggingface-cli, so you don’t have to download prior the model by yourself. Just pass the HuggingFace ID of the model directly through the prompt as positional argument (mandatory):
(neural-speed) $ python scripts/convert.py openlm-research/open_llama_7b_v2but, to be a bit more specific
(neural-speed) $ python scripts/convert.py --outtype f32 --outfile ne-f32.bin openlm-research/open_llama_7b_v2Where:
--outtype {f32,f16} is the output format, the default value is f32 if not declared.
--outfile OUTFILE is the filename/path to write the binary file to.
Really straight forward.
But what if the HuggingFace repository of the model is protected and requires a token to access it? Use the --token as option:
(neural-speed) $ python scripts/convert.py --outtype f32 --outfile ne-f32.bin openlm-research/open_llama_7b_v2 --token ju_EhihfewS4uwfn4uifskhfwfAu4wh84hkwdRemember! Make sure to never post your tokens publicly!
Then, what if you have your fine-tuned model to convert stored locally on your pc, and it’s not available on HuggingFace? No problem. Just pass the local path as positional argument:
(neural-speed) $ python scripts/convert.py --outtype f32 --outfile ne-f32.bin ./models/openlm-research_open_llama_7b_v2 In addition, scripts/convert.py makes available more two options:
--format {NE,GGUF} Convert to the GGUF or NE format, if not provided NE is the default value. GGUF is the best option if you need the interoperability with Llama.cpp.
--use_quantized_model If your model is already quantised as awq/gptq/autoround.
The whole conversion routine is contained in neural_speed/convert repository’s directory and it’s divided in several specialised files for each model type (llama, bloom, gemma, falcon, etc…).
Finally, to convert model using HuggingFace’s PEFT(Parameter-Efficient Fine-Tuning) adapter, you need to merge the PEFT adapter into the model and save it locally before using scripts/convert.py:
(neural-speed) $ python scripts/load_peft_and_merge.py --model_name_or_path meta-llama/Llama-2-7b-hf --peft_name_or_path dfurman/llama-2-7b-instruct-peft --save_path ./Llama-2-7b-hf-instruct-peftwhere
--model_name_or_path MODEL_NAME_OR_PATH The model checkpoint for weights initialization. Set to model ID of HuggingFace model hub, or local path to the model.
--peft_name_or_path PEFT_NAME_OR_PATH The PEFT model checkpoint for weights initialization. Set to model ID of HuggingFace model hub, or local path to the model.
--save_path SAVE_PATH Path to save merged model checkpoint.
All the options are mandatory, no defaults value.

Step 2: quantization with scripts/quantize.py
Ok, next step after conversion comes the quantization of weights. Technically, our goal is to reduce the original model size from FP32 to INT4 or INT8, hopefully getting a real low precision loss.
For example, to quantize a previously converted model to INT4 you can simply use the prompt:
(neural-speed) $ python scripts/quantize.py --model_name llama2 --model_file ne-f32.bin --out_file ne-q4_j.bin
where,
--model_name MODEL_NAME The model name (for example, llama, llama2, mpt, falcon, gptj, starcoder, dolly, etc…).
--model_file MODEL_FILE Filepath to the previously converted fp32 model binary file.
--out_file OUT_FILE Filepath to the resulted quantized model.
Consider that in the previous prompt, the three inputs were mandatory, while a few options were omitted, but they have a default value:
--weight_dtype {int4,int8,fp8,fp8_e5m2,fp8_e4m3,fp4,fp4_e2m1,nf4} Data type of quantized weights. The default is int4 (tipically, it is exactly what we want).
--group_size {-1,32,128} The group size passed as integer-only. The default is 32. BTW, I often suggest to use a value of 128 for group_size.
--compute_dtype {fp32,fp16,bf16,int8} Data type of GeMM computation. The default value is fp32, but for our local/bare-metal run int8 is preferable.
So, in summary, a better prompt to quantize weights of fp32 ggml bin could be:
(neural-speed) $ python scripts/quantize.py --model_name llama2 --model_file ne-f32.bin --out_file ne-q4_j.bin --weight_dtype int4 --group_size 128 --compute_dtype int8In addition, we have also the opportunity to pass other options to the prompt:
--build_dir BUILD_DIR Path to the build directory.
--config CONFIG Path to the optional configuration file.
--nthread NTHREAD Number (integer-only) of threads to use. The default is 1.
--alg {sym,asym} Quantization algorithm to use: symmmetric or asymmetric. The default if not declared is sym.
--scale_dtype {fp32,bf16,fp8} Data type of scales: bf16 (brain float), fp32 or fp8. Default is fp32.
--use_ggml This option enables the ggml format for quantization and inference. (Don’t use if you really do not need it.)
--one_click_run {True,False} One-click for quantization and inference.
So, in alternative, if you need you could run ggml q4_0 (= 32 numbers in chunk, 4 bits per weight, 1 scale value at 32-bit float, 5 bits per value in average, each weight is given by the common scale * quantized value) format with the following prompt:
(neural-speed) $ python scripts/quantize.py --model_name llama2 --model_file ne-f32.bin --out_file ne-q4_0.bin --weight_dtype int4 --use_ggmlIn conclusion, the final prompt I suggest for an optimized INT4 model with group size 128 results:
(neural-speed) $ python scripts/quantize.py --model_name llama2 --model_file ne-f32.bin --out_file ne-q4_j.bin --weight_dtype int4 --group_size 128 --compute_dtype int8Supported Matrix Multiplication Data Types (MatMul) Combinations
Neural Speed supports INT4, INT8, FP8 (E4M3, E5M2), FP4 (E2M1), and NF4 weight-only quantization; and FP32/FP16/BF16/INT8 computation forward matrix multiplication on x86_64 platforms.
As per BesTLA specifications, in the following table the supported data types combinations for matmul operations:
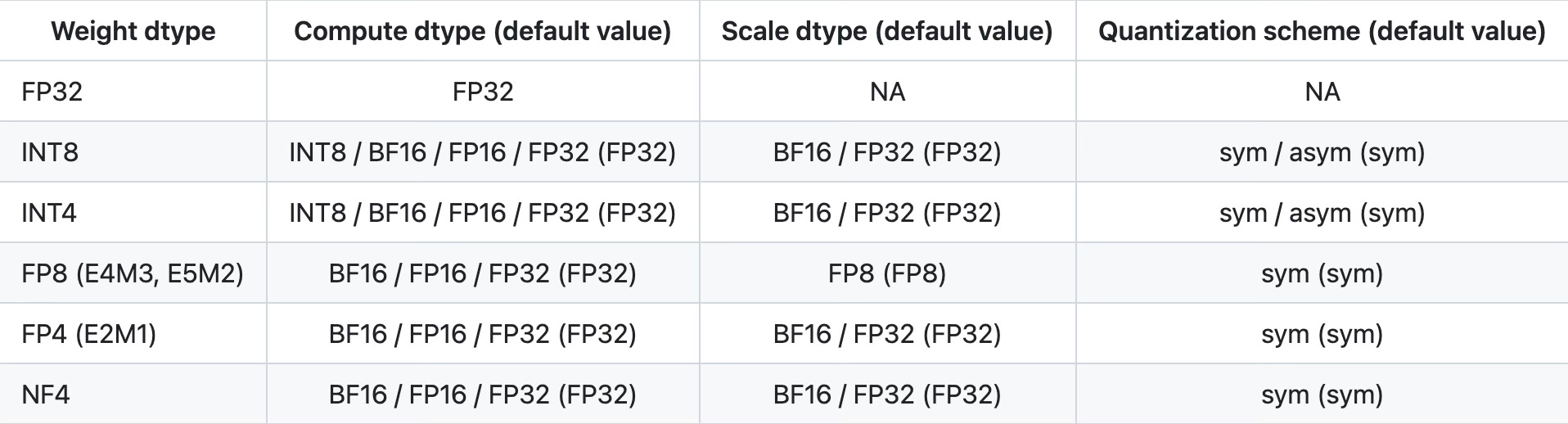
Step 3: inference with scripts/inference.py
Let us continue with the inference process. The minimal prompt to use the out-of-the-box script inference.py is the folliwing
(neural-speed) $ python scripts/inference.py --model_name llama2 --model ne-q4_j.bin where:
--model_name MODEL_NAME The model name (for example, llama, llama2, mpt, falcon, gptj, starcoder, dolly, etc…).
-m, --model MODEL_FILE Filepath to the previously quantized model binary file.
That prompt will load the model onto the RAM and it will start a useless natural language generation flow as it will be totally random, but it can be used as preliminary test over the performance, measured in terms of token/second.
To make the inference a little more useful, the developers of Neural Speed provided us with several more options you can provision, as
--build_dir BUILD_DIR Path to the build directory.
-p, --prompt "PROMPT" Prompt to start generation with. Note: between quotation marks.
-f, --file FILE Pathfile to a text file containing the prompt (for larger prompts).
--tokenizer TOKENIZER The path of the chatglm tokenizer; default: THUDM/chatglm-6b.
-n, --n_predict NUMBER Integer number of tokens to predict; default value= 0 (-1 = all).
-t, --threads THREADS Integer number of threads to use during computation; default value is 56.
-b, --batch_size_truncate BATCH Batch size (int) for prompt processing; default = 512.
-c, --ctx_size SIZE Size (int) of the prompt context; default = 512. Note: can not be larger than specific model's context window length.
-s, --seed SEED NG seed (int); default = -1. (Note: use random seed for < 0.)
--repeat_penalty PENALTY Penalize repeat sequence of tokens (float); default = 1.1. (Note: = 1.0 to disable.)
--color Colorise output to distinguish prompt and user input from generations (default: False).
--keep KEEP Number of tokens (integer) to keep from the initial prompt; default = 0. (Note: = -1 for all.)
--shift-roped-k Use ring-buffer and thus do not re-computing after reaching ctx_size (default: False).
--memory-f32 Use FP32 for the data type of K-/V- memory.
--memory-f16 Use FP16 for the data type of K-/V- memory.
--memory-auto Try with BesTLA flash attention managed format for K-/V-memory (Currently GCC13 & AMX required); fall back to FP16 if failed (default option for K-/V-memory).
--one_click_run One-click for quantization and inference (default False).
For example,
(neural-speed) $ python scripts/inference.py --model_name llama2 -m ne-q4_j.bin -c 512 -b 1024 -n 256 -t 4 --color -p "The boy runs on the hill and see"If you want to generate a fixed output, reasonable fixed, you can set --seed argument:
(neural-speed) $ python scripts/inference.py --model_name llama2 -m ne-q4_j.bin -c 512 -b 1024 -n 256 -t 4 --color -p "The boy runs on the hill and see" --seed 12Then, if you want to reduce repeated generated tokens, please set --repeat_penalty (that should be a float value > 1.0, for example:
(neural-speed) $ python scripts/inference.py --model_name llama2 -m ne-q4_j.bin -c 512 -b 1024 -n 256 -t 4 --color -p "The boy runs on the hill and see" --repeat_penalty 1.2via NUMA
Intel’s Team recommends to use numactl to bind cores in Intel CPUs for better performance.
To install numactl is really simple, at least on Ubuntu; just type
$ sudo apt update && sudo apt install numactlThen, you can run inference with
(neural-speed) $ numactl -m 0 -C 0-<physic_cores-1> python scripts/inference.py --model_name llama -m ne-q4_j.bin -c 512 -b 1024 -n 256 -t <physic_cores> --color -p "She opened the door and see"where you need to set physic_cores as per the number of max threads available on your CPU. In my case this value is 8, so
(neural-speed) $ numactl -m 0 -C 0-7 python scripts/inference.py --model_name llama2 -m ne-q4_j.bin -c 512 -b 1024 -n 256 -t 8 --color -p "The boy runs on the hill and see"Full Example
For your comfort, I report all the steps using openlm-research’s open_llama_7b_v2 as model to convert and quantize (INT4, group size 128):
(neural-speed) $ cd neural-speed
(neural-speed) $ mkdir outfile
(neural-speed) $ mkdir models
(neural-speed) $ huggingface-cli download --resume-download --local-dir models/openlm-research_open_llama_7b_v2 --local-dir-use-symlinks False openlm-research/open_llama_7b_v2
(neural-speed) $ python scripts/convert.py --outtype f32 --outfile outfile/open_llama_7b_v2-f32.bin models/openlm-research_open_llama_7b_v2
(neural-speed) $ python scripts/quantize.py --model_name llama2 --model_file outfile/open_llama_7b_v2-f32.bin --out_file outfile/open_llama_7b_v2-q4_j.bin --weight_dtype int4 --group_size 128 --compute_dtype int8
(neural-speed) $ python scripts/inference.py --model_name llama2 -m outfile/open_llama_7b_v2-q4_j.bin -c 512 -b 1024 -n 256 -t 4 --color -p "The boy runs on the hill and see"The one-click script run.py
To make your life easier, Neural Speed’s developers coded a straight forward all-in-one one-click script that condense all the steps (conversion, quantization and inference); we already saw in the first article when entered in touch with Neural Speed.
(neural-speed) $ python scripts/run.py openlm-research/open_llama_7b_v2where the only mandatory argument is the model to parse as argument, local or through the HuggingFace’s ID
--model_name_or_path MODEL_NAME_OR_PATH The model checkpoint for weights initialization. Set to model ID of HuggingFace model hub, or local path to the model.
But, several other optional arguments are available:
--build_dir BUILD_DIR Path to build directory (optional, if not provided it will be cached).
--weight_dtype {int4,int8,fp8,fp8_e5m2,fp8_e4m3,fp4,fp4_e2m1,nf4} Data type of quantized weights. The default is int4 (tipically, it is exactly what we want).
--model_type MODEL_TYPE Set the model type manually (for example, llama, llama2, mpt, falcon, gptj, starcoder, dolly, etc…).
--alg {sym,asym} Quantization algorithm to use: symmmetric or asymmetric. The default if not declared is sym.
--group_size {-1,32,128} The group size passed as integer-only. The default is 32. BTW, I often suggest to use a value of 128 for group_size.
--scale_dtype {fp32,bf16,fp8} Data type of scales: bf16 (brain float), fp32 or fp8. Default is fp32.
--compute_dtype {fp32,fp16,bf16,int8} Data type of GeMM computation. The default value is fp32, but for our local/bare-metal run int8 is preferable.
--format {NE,GGUF} Convert to the GGUF (.gguf) or NE format, if not provided NE is the default value. GGUF is the best option if you need the interoperability with Llama.cpp.
--use_ggml This option enables the ggml format for quantization and inference. If not made explicit, it’s disabled. (Don’t use if you really do not need it.)
-p, --prompt "PROMPT" Prompt to start generation with. Note: between quotation marks.
-f, --file FILE Pathfile to a text file containing the prompt (for larger prompts).
-n N_PREDICT, --n_predict N_PREDICT Integer number of tokens to predict; default value= 0 (-1 = all).
-t, --threads THREADS Integer number of threads to use during computation; default value is 56.
-b, --batch_size_truncate BATCH Batch size (int) for prompt processing; default = 512.
-c, --ctx_size SIZE Size (int) of the prompt context; default = 512. Note: can not be larger than specific model's context window length.
-s, --seed SEED NG seed (int); default = -1. (Note: use random seed for < 0.)
--repeat_penalty PENALTY Penalize repeat sequence of tokens (float); default = 1.1. (Note: = 1.0 to disable.)
--color Colorise output to distinguish prompt and user input from generations (default: False).
--keep KEEP Number of tokens (integer) to keep from the initial prompt; default = 0. (Note: = -1 for all.)
--shift-roped-k Use ring-buffer and thus do not re-computing after reaching ctx_size (default: disabled).
--token TOKEN Access token for models that require it on HuggingFace (LLaMa2, etc).
Preliminary Performance Benchmarks
On my 2017 Intel Xeon E3-1240v6 3.7GHz, quad-cores with octa-threads, with 64GB DDR4 2600MHz (n_threads = 4 / 8 | AVX = 1 | AVX2 = 1 | FMA = 1 | F16C = 1) the quantization process took
~1m 20s for open/llama_7b_v2
~55m 19s for meta/llama_Llama-2-70b-hf
conversion took
~3m 23s for open/llama_7b_v2
~52m 10s for meta/llama_Llama-2-70b-hf
For References
Details of quantization level methods:
q4_0 = 32 numbers in chunk, 4 bits per weight, 1 scale value at 32-bit float (5 bits per value in average), each weight is given by the common scale * quantized value.
q4_1 = 32 numbers in chunk, 4 bits per weight, 1 scale value and 1 bias value at 32-bit float (6 bits per value in average), each weight is given by the common scale * quantized value + common bias.
q4_2 = same as q4_0, but 16 numbers in chunk, 4 bits per weight, 1 scale value that is 16-bit float, same size as q4_0 but better because chunks are smaller.
q4_3 = already dead, but analogous: q4_1 but 16 numbers in chunk, 4 bits per weight, scale value that is 16 bit and bias also 16 bits, same size as q4_1 but better because chunks are smaller.
q5_0 = 32 numbers in chunk, 5 bits per weight, 1 scale value at 16-bit float, size is 5.5 bits per weight
q5_1 = 32 numbers in a chunk, 5 bits per weight, 1 scale value at 16 bit float and 1 bias value at 16 bit, size is 6 bits per weight.
q8_0 = same as q4_0, except 8 bits per weight, 1 scale value at 32 bits, making total of 9 bits per weight.
Bibliography
Notable differences between q4_2 and q5_1 quantization? on r/LocalLLaMA
Neural Speed documentation on Github
numactl - Linux man page on linux.die.net
* This content has been produced by human hands.